2.2. Gradient Methods#
Recall that our aim is to solve/tackle the following unconstrained optimization problem:
where \(\vw\) is the optimization variable; \(f: \RR^d \to \RR\) is the objective function which is assumed to be lower bounded. There are no explicit constraints on \(\vw\).
To make our life easier, we assume that \(f\) is (continuously) differentiable everywhere. As discussed in the last subsection, the task of tackling the optimization problem can be cast as searching for \(\vw^*\) such that
The gradient (a.k.a. first-order) method is an efficient numerical scheme for achieving the above goals. In its simplest form, the gradient method can be described as:
Algorithm 2.1 (Gradient Method)
Input: initial point \(\vw^0\), stepsize sequence \(\{ \gamma_k \}_{k \geq 0}\), max. no. of iterations \(K\).
For \(k=0,1,2,..., K-1\),
Output: last iterate \(\vw^K\), or the solution sequence \(\{ \vw^k \}_{k=1}^K\).
Insight (Gradient Method)
The update recursion of gradient method is inspired by the 2nd order Taylor expansion of \(f\). Consider the current iterate at \(\vw\) and our goal is to search for a new iterate \(\vw' = \vw + \gamma \Delta\) such that \(f(\vw')\) is minimized, where \(\Delta\) is the search direction. We observe
For small step size with \(\gamma \approx 0\), the search direction \(\Delta\) which minimizes \(f(\vw')\) is to pick
This hence inspires the gradient method recursion \(\vw' = \vw - \gamma \nabla f(\vw)\).
The gradient method (and more importantly, its stochastic version) has become the backbone for modern large scale optimization software packages that includes LLM optimization. Part of the reason is that there exists efficient functions (e.g., autograd in Pytorch) for calculating the gradient of complicated objective functions which greatly simplify the implementation of the algorithm.
In the remainder of this chapter, we will analyze the convergence of gradient methods to give ourselves a taste of how well they will perform under different settings in theory, followed by a simple numerical example.
2.2.1. Convergence for Smooth Objective Function#
Assumption 2.1 (Smooth Objective Function)
There exists \(L \geq 0\) such that for any \(\vw, \vw' \in \mathbb{R}^d\), we have
Theorem 2.6 (Convergence of Gradient Method (Smooth Case))
Under Assumption 2.1 and suppose that the step size satisfies \(\gamma_k \leq 1/L\). For any \(K \geq 1\), the following holds:
Proof (Gradient Method for Smooth Objective Function)
We begin by observing that under Assumption 2.1, it holds for any \(k \geq 0\) that,
By noting that \(\vw^{k+1} - \vw^k = - \gamma_k \nabla f(\vw^k)\) and \(\gamma_k \leq 1/L\), we have
This implies
Summing both sides from \(k=0\) to \(k=K-1\) yields the desired result.
Particularly, we notice that by picking \(\gamma_k = 1/L\) for all \(k\), we have
In other words, in less than or equal to \(K\) iterations, the gradient method finds an \({\cal O}(1/K)\) stationary solution.
2.2.2. Convergence for Convex and Smooth Objective Function#
Assumption 2.2 (Convex Objective Function)
The objective function \(f(\vw)\) is convex and is lower bounded.
Theorem 2.7 (Convergence of Gradient Method (Convex and Smooth Case))
Under Assumption 2.1, Assumption 2.2, and suppose that the selected step size is constant satisfying \(\gamma_k = \gamma \leq 1/L\) for any \(k\). Then, for any \(K \geq 1\), the following holds:
Proof (Gradient Method for Convex & Smooth Objective Function)
We begin the proof by continuing from the proof of Theorem 2.6 and observe that
Furthermore, from the convexity of \(f\), we notice that
Thus
We observe that
This implies
Now, we notice that
Since \(f( \vw^{K} ) \leq f( \vw^{K-1} ) \leq \cdots \leq f(\vw^1 )\), the above implies that
This concludes the proof.
In particular, setting \(\gamma = 1/L\) yields
2.2.3. Convergence for Strongly Convex and Smooth Objective Function#
Assumption 2.3 (Strongly Convex Objective Function)
The objective function \(f(\vw)\) is \(\mu\)-strongly convex, with \(\mu > 0\). In particular, for any \(\vw', \vw \in \mathbb{R}^d\), it holds
Notice that an immediate consequence of the above assumption is that the optimal solution \(\vw^\star\) to the optimization problem is now unique.
Theorem 2.8 (Convergence of Gradient Method (Strongly Convex and Smooth Case))
Under Assumption 2.1, Assumption 2.3, and suppose that the selected step size is constant satisfying \(\gamma_k = \gamma \leq 1/L\) for any \(k\). Then, for any \(k \geq 1\), the following holds:
Proof (Gradient Method for Strongly Convex & Smooth Objective Function)
We begin the proof by observing that
Notice that by strong convexity, we have
This yields
Notice that
and thus the last term inside the bracket is upper bounded by \(0\). This concludes the proof for the theorem.
Particularly, if we take \(\gamma = 1/L\), we have
Thus the gradient method converges linearly towards the optimal solution.
2.2.3.1. Remarks and Further Readings#
The above theorems present the finite-time convergence of the gradient method under various cases. For additional information, readers are referred to Chapter 1 & 2 of [Bertsekas, 1997] for a more comprehensive treatment on unconstrained optimization. For recent developments, readers are referred to [Lan, 2020].
2.2.4. Numerical Examples#
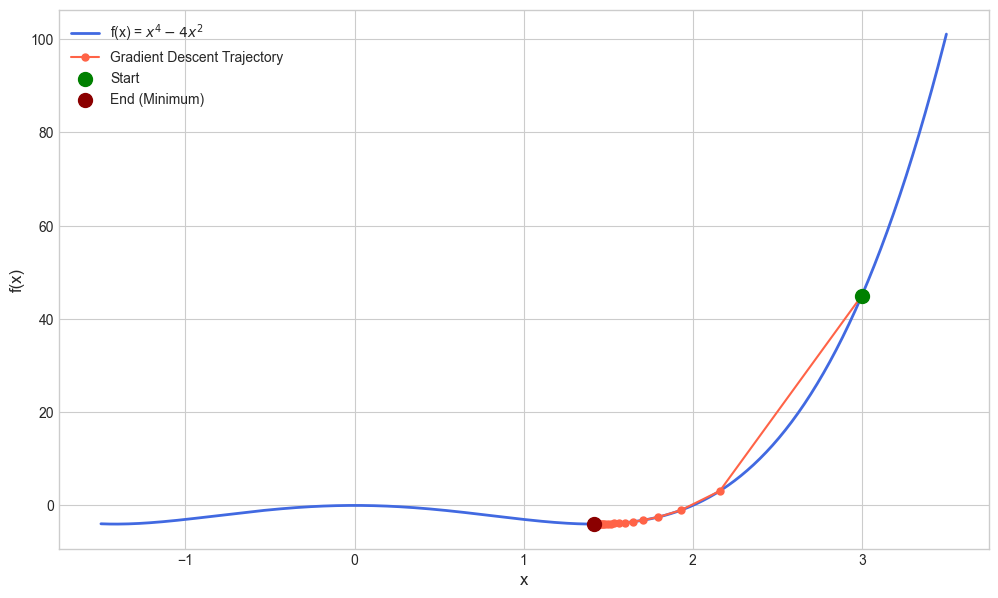
Example 1: The following code demonstrates the application of gradient descent method on minimizing \(f(x) = x^4 - 4x^2\).
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**4 - 4*x**2
def df(x):
return 4*x**3 - 8*x
start_x = 3; learning_rate = 0.01; n_iterations = 50
trajectory_x = [start_x]; trajectory_y = [f(start_x)]
x = start_x
for i in range(n_iterations):
gradient = df(x)
# Gradient descent step!
x = x - learning_rate * gradient
# Store the new position to plot later
trajectory_x.append(x); trajectory_y.append(f(x))
if i % 5 == 0:
print(f"Iteration {i+1}: x = {x:.4f}, f(x) = {f(x):.4f}, gradient = {gradient:.4f}")
# Plot the function and trajectory
x_range = np.linspace(-1.5, 3.5, 400); y_range = f(x_range)
plt.style.use('seaborn-v0_8-whitegrid'); plt.figure(figsize=(12, 7))
plt.plot(x_range, y_range, label='f(x) = $x^4 - 4x^2$', color='royalblue', linewidth=2)
plt.plot(trajectory_x, trajectory_y, 'o-', color='tomato', label='Gradient Descent Trajectory', markersize=5)
# Start and end points
plt.scatter(trajectory_x[0], trajectory_y[0], color='green', s=100, zorder=5, label='Start')
plt.scatter(trajectory_x[-1], trajectory_y[-1], color='darkred', s=100, zorder=5, label='End (Minimum)')
# Title & labels
plt.xlabel('x', fontsize=12); plt.ylabel('f(x)', fontsize=12)
plt.legend(fontsize=10); plt.grid(True)
# Display the final plot
plt.show()
Iteration 1: x = 2.1600, f(x) = 3.1054, gradient = 84.0000
Iteration 6: x = 1.5990, f(x) = -3.6899, gradient = 4.6609
Iteration 11: x = 1.4818, f(x) = -3.9617, gradient = 1.4243
Iteration 16: x = 1.4411, f(x) = -3.9941, gradient = 0.5332
Iteration 21: x = 1.4252, f(x) = -3.9990, gradient = 0.2135
Iteration 26: x = 1.4188, f(x) = -3.9998, gradient = 0.0877
Iteration 31: x = 1.4161, f(x) = -4.0000, gradient = 0.0364
Iteration 36: x = 1.4150, f(x) = -4.0000, gradient = 0.0152
Iteration 41: x = 1.4145, f(x) = -4.0000, gradient = 0.0063
Iteration 46: x = 1.4144, f(x) = -4.0000, gradient = 0.0027
Example 2: The following code demonstrates the application of gradient descent method on minimizing \(f(x) = x_1^2 + 4x_2^2 + 2x_1 x_2\).
import numpy as np
import matplotlib.pyplot as plt
def f(x1, x2):
return x1**2 + 4*x2**2 + 2*x1*x2
def grad_f(x):
return np.array([2*x[0] + 2*x[1], 8*x[1] + 2*x[0]])
start_point = np.array([4.0, 2.0]); learning_rate = 0.1; n_iterations = 25
trajectory = [start_point]; x = start_point
for i in range(n_iterations):
gradient = grad_f(x)
# Gradient Descent
x = x - learning_rate * gradient
# Store the new position to plot later
trajectory.append(x)
if i % 5 == 0:
print(f"Iteration {i+1}: x = ({x[0]:.4f}, {x[1]:.4f}), f(x) = {f(x[0], x[1]):.4f}, gradient = ({gradient[0]:.4f}, {gradient[1]:.4f})")
# Convert trajectory to a numpy array for easier slicing
trajectory = np.array(trajectory)
# --- Plot the Function's Contours and the Trajectory ---
x1_range = np.linspace(-7.5, 7.5, 100)
x2_range = np.linspace(-7.5, 7.5, 100)
X1, X2 = np.meshgrid(x1_range, x2_range); Z = f(X1, X2)
plt.style.use('seaborn-v0_8-whitegrid')
plt.figure(figsize=(10, 8))
plt.contourf(X1, X2, Z, levels=50, cmap='viridis', alpha=0.8)
plt.colorbar(label='f($x_1, x_2$)')
plt.contour(X1, X2, Z, levels=50, colors='white', linewidths=0.5, alpha=0.5)
plt.plot(trajectory[:, 0], trajectory[:, 1], 'o-', color='tomato', label='Gradient Descent Trajectory')
plt.scatter(trajectory[0, 0], trajectory[0, 1], color='lime', s=100, zorder=5, label='Start')
plt.scatter(trajectory[-1, 0], trajectory[-1, 1], color='red', s=100, zorder=5, label='End')
plt.xlabel('$x_1$', fontsize=14); plt.ylabel('$x_2$', fontsize=14)
plt.legend(fontsize=10); plt.axis('equal')
plt.show()
final_x = trajectory[-1]
final_f_val = f(final_x[0], final_x[1])
Iteration 1: x = (2.8000, -0.4000), f(x) = 6.2400, gradient = (12.0000, 24.0000)
Iteration 6: x = (1.2628, -0.3823), f(x) = 1.2138, gradient = (2.0467, -0.6182)
Iteration 11: x = (0.5960, -0.1805), f(x) = 0.2704, gradient = (0.9658, -0.2924)
Iteration 16: x = (0.2813, -0.0852), f(x) = 0.0602, gradient = (0.4558, -0.1380)
Iteration 21: x = (0.1327, -0.0402), f(x) = 0.0134, gradient = (0.2151, -0.0651)

2.2.5. Accelerated Variants of Gradient Methods#
Besides the plain gradient methods, there exist several accelerated variants that aim to improve convergence rates. These methods are particularly useful for ill-conditioned problems where the landscape of the objective function varies significantly in different directions.
One of the most well-known accelerated methods is Nesterov’s Accelerated Gradient (NAG) method [Nesterov, 2018], which incorporates momentum into the gradient update. The key idea is to use a combination of the current gradient and the previous update direction to inform the next step. As summarized below:
Algorithm 2.2 (Nesterov’s Accelerated Gradient (NAG) Method)
Input: initial point \(\vw^0\), stepsize sequence \(\{ \gamma_k \}_{k \geq 0}\), max. no. of iterations \(K\), momentum sequence \(\{ \beta_k \}_{k \geq 0}\).
Set \(\vw^{-1} = \vw^0\).
For \(k=0,1,2,..., K-1\),
Output: last iterate \(\vw^K\).
An important property of NAG method is its ability to achieve a faster convergence rate than standard GD, particularly for convex functions. For instance, in the case of strongly convex \(f(\vw)\) [cf. under the same setting as Theorem 2.8], with an appropriate choice of \(\gamma, \beta\), it can be shown that
which is faster compared to Theorem 2.8 which only achieves \({\cal O}( (1-\mu/L)^k )\). For other settings such as with convex and smooth \(f(\vw)\), NAG also achieves an improved convergence rate of \({\cal O}(1/k^2)\) compared to the \({\cal O}(1/k)\) rate in Theorem 2.7. In fact, as proven in [Nesterov, 2018], the NAG method achieves the optimal convergence rate for both convex and strongly convex functions.
Another popular accelerated gradient method is the Heavy-Ball Method [Polyak, 1964], which also incorporates momentum but in a slightly different manner than the Nesterov’s method. The update rule for the Heavy-Ball method is given by:
Algorithm 2.3 (Heavy-Ball Method)
Input: initial point \(\vw^0\), stepsize sequence \(\{ \gamma_k \}_{k \geq 0}\), momentum sequence \(\{ \beta_k \}_{k \geq 0}\), max. no. of iterations \(K\).
For \(k=0,1,2,..., K-1\),
Output: last iterate \(\vw^K\).
Unlike NAG which computes the gradient at the look-ahead point \({\bf y}^k = \vw^k + \beta_k ( \vw^k - \vw^{k-1} )\), the Heavy-Ball method computes the gradient at the current point \(\vw^k\). The Heavy-Ball method has been shown to be effective in practice, although its theoretical convergence properties are not as well-established as those of NAG, where similar acceleration guarantees exist only for quadratic objective functions. An excellent tutorial on the momentum method can be found in [Goh, 2017].