3. Introduction to Large Language Models#
(Pytorch nanoGPT code is from: karpathy/nanoGPT)
3.1. Intro#
This chapter serves as an introduction to the basic concepts in Large Language Model (LLM) architectures and training. In the first section we will introduce the basic blocks and mechanisms of the transformer architecture, which most modern LLMs are based on. Next, we will introduce the basic ideas involved in the training of the LLMs. In addition, this notebook is intended to provide a runnable code implementation of the nanoGPT model and a basic training pipeline.
3.2. Transformer Architecture#
Most modern LLMs are based on the decoder-only transformer model architecture. Essentially, the decoder-only transformer (we will refer to it simply as transformer) is a deep learning model built from multiple transformer layers as well as an embedding and a Language Model (LM) Head layer in the input and output, respectively.
The transformer model takes as input sequences of tokens and outputs a probability distribution over possible next tokens for each input position. Those probability distributions are then used to generate the output text of the model.
Next we will describe in detail its components and provide the corresponding codes.
import math
import torch
import torch.nn as nn
from torch.nn import functional as F
from dataclasses import dataclass
import inspect
import numpy as np
from typing import Callable, Iterable, Tuple
3.2.1. Tokenizer#
Neural Networks such as the transformer work with numbers, not text. Therefore the input texts need to be converted to sequences of numbers before the transformer can process them. Thus, the text is first converted into discrete components known as tokens, which constitute the model’s vocabulary \(V\). Each of the tokens corresponds to a unique number, the token ID.
The module that performs the conversion is called the tokenizer. It is technically considered a preprocessing module, separate from the transformer architecture. There are a number of different approaches to tokenization with one of the most popular being Byte Pair Encoding (BPE), which performs subword tokenization by iteratively merging the most frequent pairs of symbols in the text. An important parameter of the tokenizer is the vocabulary size \(V\), which is the total number of unique tokens it can produce and the model can recognize.
In short, the tokenizer, given as input raw text sequences, outputs a batch of token sequences and their corresponding IDs, which normally have a shape \([B, L]\). Here \(B\) is the batch size that determines the number of sequences (or samples) the transformer will process in parallel and \(L\) is the number of tokens per sequence.
The batch of token ID sequences will then be converted to a batch of embeddings vectors (one embedding per token) by the embedding layer of the transformer.
from transformers import AutoTokenizer
# Load the GPT-2 tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
print("Pad token/ID:", tokenizer.pad_token, tokenizer.convert_tokens_to_ids(tokenizer.pad_token))
print("Vocabulary size |V|:", tokenizer.vocab_size)
# Example batch of texts
texts = [
"The cat sat on the mat",
"A quick brown fox jumps over the lazy dog!"
]
# Tokenize the batch with padding, L=10
encoded = tokenizer(texts, return_tensors="pt", max_length=10 , truncation=True, padding="max_length" )
tokens = [tokenizer.convert_ids_to_tokens(ids) for ids in encoded["input_ids"]]
print("Tokens:", *tokens, sep="\n")
print("Input IDs:\n", encoded["input_ids"])
print("Attention Mask:\n", encoded["attention_mask"])
Pad token/ID: <|endoftext|> 50256
Vocabulary size |V|: 50257
Tokens:
['The', 'Ġcat', 'Ġsat', 'Ġon', 'Ġthe', 'Ġmat', '<|endoftext|>', '<|endoftext|>', '<|endoftext|>', '<|endoftext|>']
['A', 'Ġquick', 'Ġbrown', 'Ġfox', 'Ġjumps', 'Ġover', 'Ġthe', 'Ġlazy', 'Ġdog', '!']
Input IDs:
tensor([[ 464, 3797, 3332, 319, 262, 2603, 50256, 50256, 50256, 50256],
[ 32, 2068, 7586, 21831, 18045, 625, 262, 16931, 3290, 0]])
Attention Mask:
tensor([[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
Note that Ġ is a special symbol that the particular tokenizer usees to represent a space before a word.
3.2.2. Embedding Layer#
The input tokens are discrete and therefore not directly optimizable by gradient-based methods. Thus they need to be converted to continuous, dense vectors that capture semantic meanings and can be learned and optimized by the transformer. This is done by the embedding layer.
The embedding layer is essentially a trainable look-up table. It takes as input the token IDs and outputs the corresponding rows - which are the embedding vectors for the specified token IDs. It has shape (\(|V|\), \(d_{\text{model}}\)), where \(d_{\text{model}}\) is the dimension of the embedding vectors. Bellow is an example of how it looks in code:
embedding.weight = [
[e1_1, e1_2, ..., e1_d], # embedding for token 1
[e2_1, e2_2, ..., e2_d], # embedding for token 2
...
[en_1, en_2, ..., en_d], # embedding for token n
]
# where n = |V| and d = d_model
Therefore, the embedding layer for an input tensor of shape \([B, L]\) it will output a tensor of shape \([B, L, d_{\text{model}}]\).
V = tokenizer.vocab_size #|V| = 50256
d_model = 3 # Small value for illustration purposes. E.g., nanoGPT uses d_model=768
embedding = nn.Embedding(num_embeddings=V, embedding_dim=d_model)
# Token IDs from previous example.
input_ids = encoded["input_ids"]
print("Token IDs:\n", input_ids)
embedded_vectors = embedding(input_ids)
print("Embedding vectors:\n", embedded_vectors)
print("Embedding Layer output shape:", embedded_vectors.shape) # Output shape [B=2, L=10, d_model=3]
Token IDs:
tensor([[ 464, 3797, 3332, 319, 262, 2603, 50256, 50256, 50256, 50256],
[ 32, 2068, 7586, 21831, 18045, 625, 262, 16931, 3290, 0]])
Embedding vectors:
tensor([[[-1.2959, 1.1001, 0.0517],
[ 0.0559, 0.5397, 1.3118],
[-1.6884, -0.0172, -0.0680],
[ 0.6226, -0.2761, -0.2921],
[-0.5190, -0.6476, -0.2988],
[-1.5228, 0.5229, 0.0332],
[-1.4930, 1.0943, -2.0135],
[-1.4930, 1.0943, -2.0135],
[-1.4930, 1.0943, -2.0135],
[-1.4930, 1.0943, -2.0135]],
[[-0.5203, -0.1618, 1.1561],
[ 0.4259, -1.4042, -0.0132],
[-0.2340, -0.5839, -0.6909],
[-1.4637, -0.5112, 0.4132],
[-0.1768, -0.6902, -0.5625],
[ 0.6028, -0.0063, -0.2933],
[-0.5190, -0.6476, -0.2988],
[ 0.3882, -2.2415, -0.6846],
[-0.2044, 0.2900, 0.1939],
[ 0.5053, -0.3499, -0.9881]]], grad_fn=<EmbeddingBackward0>)
Embedding Layer output shape: torch.Size([2, 10, 3])
3.2.3. Self-attention#
Self-attention is a mechanism that transforms the representation of each token in a sequence by relating it to different tokens of the sequence. This new representation can then be used by the model to e.g., predict the next word of the sequence.
For example, lets say we have the sentence “The cat sat on the mat”. We can assume a simple word tokenizer and an embedding layer which results in one embedding vector for each word:
The |
cat |
sat |
on |
the |
mat |
|---|---|---|---|---|---|
\(e_1\) |
\(e_2\) |
\(e_3\) |
\(e_4\) |
\(e_5\) |
\(e_6\) |
If we wanted to create a model to predict the next word, we could directly just use an MLP+softmax (see bellow for more details about softmax) with input one of the embedding vectors like the above and output a probability distribution over the vocabulary.
However, currently each embedding \(e_i\) contains information only for the particular word it embeds, regardless of the rest of the sequence. So for example given \(e_5\) the model would just predict the most probable word after a “the”, which is certainly not “mat”. Instead, with a self-attention layer \(e_5\) will be transformed into \(e_5' = f(e_1, e_2, e_3, e_4, e_5)\), now containing the context. Here \(f()\) represents the self-attention transformation that produces the contextualized embedding, which we will describe in details in the next part.
More on the Softmax Operator Given a vector of logits \(\mathbf{z} = [z_1, z_2, \dots, z_{|V|}] \in \mathbb{R}^{|V|} \), where \(|V| \) is the vocabulary size, the softmax function is defined component-wise as:
The output is a probability vector \(\mathbf{p} = \text{softmax}(\mathbf{z}) \in \mathbb{R}^{|V|} \) such that:
\( p_i > 0 \) for all \( i \)
\( \sum_{i=1}^{|V|} p_i = 1 \)
Thus, \(\mathbf{p} \in \Delta^{|V|-1} \), the probability simplex.
Bellow we will describe how self-attention is computed.
3.2.4. Scaled Dot-Product Attention#
Assume batch size B=1
X is the embedding matrix (contains the embedding vectors of \(L\) tokens)
Assume single attention layer after the embedding layer
Input matrix:
We apply learned projection matrices:
To obtain the queries, keys, and values:
Attention logits matrix \(QK^T\):
Attention weight matrix \(A\):
Note that \(a_{ij}\) is the attention weight of query \(q_i\) wrt key \(k_j\) and indicates the level of attention that token \(i\) pays on token \(j\).
Attention output \(Z\):
\(Z\) is the output of the attention layer, which weights the value vectors \(v_i\) based on the computed attention weights. Each \(z_i\) combines information from different value vectors (corresponding to different tokens) according to the attention given to each key by each query.
# Numpy implementation of dot-product attention:
# Define embedding vectors for tokens (3 tokens/sq_len, 4-dimensional embeddings)
embedding_dim = 4
X = np.array([[0.1, 0.2, 0.3, 0.4], # Embedding for token 1
[0.5, 0.6, 0.7, 0.8], # Embedding for token 2
[0.9, 1.0, 1.1, 1.2]]) # Embedding for token 3
# Define weight matrices for the transformations (W_Q, W_K, W_V)
W_Q = np.random.rand(embedding_dim, embedding_dim) # Query weight matrix
W_K = np.random.rand(embedding_dim, embedding_dim) # Key weight matrix
W_V = np.random.rand(embedding_dim, embedding_dim) # Value weight matrix
# Compute the Q, K, V matrices by applying the transformations to the embeddings
Q = np.dot(X, W_Q) # Query matrix (Q)
K = np.dot(X, W_K) # Key matrix (K)
V = np.dot(X, W_V) # Value matrix (V)
# Define the scaling factor (sqrt of key dimension)
d_k = K.shape[1]
scaling_factor = np.sqrt(d_k)
# Compute the attention logits (Q K^T / sqrt(d_k))
logits = np.dot(Q, K.T) / scaling_factor
# Apply softmax to the logits to get attention weights
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=1, keepdims=True)
attention_weights = softmax(logits)
# Compute the output Z (weighted sum of values)
Z = np.dot(attention_weights, V)
print("Embeddings:\n", X)
print("\nQuery Matrix (Q):\n", Q)
print("\nKey Matrix (K):\n", K)
print("\nValue Matrix (V):\n", V)
print("\nAttention Logits (Q K^T / sqrt(d_k)):\n", logits)
print("\nAttention Weights (Softmax of Logits):\n", attention_weights)
print("\nOutput Z (Weighted Sum of Values):\n", Z)
Embeddings:
[[0.1 0.2 0.3 0.4]
[0.5 0.6 0.7 0.8]
[0.9 1. 1.1 1.2]]
Query Matrix (Q):
[[0.53347836 0.27715543 0.66731099 0.57934004]
[1.23817608 0.76681887 1.75295159 1.50164135]
[1.94287379 1.2564823 2.83859219 2.42394267]]
Key Matrix (K):
[[0.25299281 0.46047254 0.42366925 0.62252355]
[0.86344061 1.07663492 1.17315066 1.46137659]
[1.47388841 1.6927973 1.92263208 2.30022962]]
Value Matrix (V):
[[0.71686614 0.48664897 0.51774474 0.36683614]
[1.83740465 1.25044093 1.36988635 1.00871034]
[2.95794316 2.01423289 2.22202796 1.65058454]]
Attention Logits (Q K^T / sqrt(d_k)):
[[0.45298031 1.1942562 1.93553209]
[1.17191374 3.07280766 4.97370158]
[1.89084716 4.95135911 8.01187107]]
Attention Weights (Softmax of Logits):
[[0.13328391 0.27971113 0.58700496]
[0.0190574 0.12752973 0.85341287]
[0.0020935 0.04467209 0.95323441]]
Output Z (Weighted Sum of Values):
[[2.34581656 1.59698943 1.75652094 1.29994218]
[2.77233207 1.88771493 2.08087536 1.54426159]
[2.90319467 1.97691471 2.1803931 1.61922315]]
3.2.5. Masked (or causal) self-attention#
In practice, transformers use a version of self-attention called masked or causal self-attention. In contrast to (bidirectional) self-attention that computes attentions scores for all tokens in the sequence, masked self-attention uses a causal mask that hides future tokens, so each token can attend to itself and earlier tokens.
Example of a casual mask:
Where 1 means the token can attend, 0 means it’s masked out. Note that for simplicity each word represents a token. So,
“The” can attend only to itself.
“cat” can attend only to “The” and “cat”.
“mat” can attend to everything in this sentence.
Usually this masking is done by setting the \(q_i k_j^T\) with \(i < j\) to \(-\infty\) in the \(QK^T\) attention logits matrix so that the application of the softmax will give zero attention weights to those positions.
In short, using the same notation as scaled-dot product attention where \(X\) is the input embedding matrix, masked self attention computes:
where
Note that \(i\) here corresponds to a row (query token index) and \(j\) to a column (key token index) of \(QK^{T}\).
# Numpy implementation of masked self-attention:
# Define embedding vectors for tokens (3 tokens/sq_len, 4-dimensional embeddings)
embedding_dim = 4
X = np.array([[0.1, 0.2, 0.3, 0.4], # Embedding for token 1
[0.5, 0.6, 0.7, 0.8], # Embedding for token 2
[0.9, 1.0, 1.1, 1.2]]) # Embedding for token 3
# Define weight matrices for the transformations (W_Q, W_K, W_V)
W_Q = np.random.rand(embedding_dim, embedding_dim) # Query weight matrix
W_K = np.random.rand(embedding_dim, embedding_dim) # Key weight matrix
W_V = np.random.rand(embedding_dim, embedding_dim) # Value weight matrix
# Compute the Q, K, V matrices by applying the transformations to the embeddings
Q = np.dot(X, W_Q) # Query matrix (Q)
K = np.dot(X, W_K) # Key matrix (K)
V = np.dot(X, W_V) # Value matrix (V)
# Define the scaling factor (sqrt of key dimension)
d_k = K.shape[1]
scaling_factor = np.sqrt(d_k)
# Compute the attention logits (Q K^T / sqrt(d_k))
logits = np.dot(Q, K.T) / scaling_factor
# Create causal mask: shape (seq_len, seq_len)
seq_len = X.shape[0]
mask = np.tril(np.ones((seq_len, seq_len))) # Lower triangular matrix including diagonal
# Apply mask: set logits where mask==0 to very large negative value (simulate -inf)
logits_masked = np.where(mask == 1, logits, -1e9)
# Apply softmax to the masked logits to get attention weights
def softmax(x):
e_x = np.exp(x - np.max(x, axis=1, keepdims=True)) # for numerical stability
return e_x / np.sum(e_x, axis=1, keepdims=True)
attention_weights = softmax(logits_masked)
# Compute the output Z (weighted sum of values)
Z = np.dot(attention_weights, V)
print("Embeddings:\n", X)
print("\nQuery Matrix (Q):\n", Q)
print("\nKey Matrix (K):\n", K)
print("\nValue Matrix (V):\n", V)
print("\nAttention Logits (Q K^T / sqrt(d_k)):\n", logits)
print("\nMask (1=keep, 0=mask):\n", mask)
print("\nMasked Attention Logits:\n", logits_masked)
print("\nAttention Weights (Softmax of Masked Logits):\n", attention_weights)
print("\nOutput Z (Weighted Sum of Values):\n", Z)
Embeddings:
[[0.1 0.2 0.3 0.4]
[0.5 0.6 0.7 0.8]
[0.9 1. 1.1 1.2]]
Query Matrix (Q):
[[0.40681885 0.67351456 0.54536208 0.40241099]
[1.26264317 1.87904402 1.23194717 1.11728042]
[2.1184675 3.08457347 1.91853226 1.83214984]]
Key Matrix (K):
[[0.21216995 0.1847136 0.65009458 0.69214268]
[0.60212113 0.6539137 1.63990299 1.55899753]
[0.99207231 1.12311379 2.62971141 2.42585238]]
Value Matrix (V):
[[0.13417439 0.42064507 0.2735804 0.41325233]
[0.34031497 1.18195098 0.83348587 1.03225912]
[0.54645556 1.94325689 1.39339134 1.65126591]]
Attention Logits (Q K^T / sqrt(d_k)):
[[0.42189239 1.10353663 1.78518087]
[1.09458978 2.87555401 4.65651823]
[1.76728717 4.64757138 7.52785559]]
Mask (1=keep, 0=mask):
[[1. 0. 0.]
[1. 1. 0.]
[1. 1. 1.]]
Masked Attention Logits:
[[ 4.21892392e-01 -1.00000000e+09 -1.00000000e+09]
[ 1.09458978e+00 2.87555401e+00 -1.00000000e+09]
[ 1.76728717e+00 4.64757138e+00 7.52785559e+00]]
Attention Weights (Softmax of Masked Logits):
[[1. 0. 0. ]
[0.14418411 0.85581589 0. ]
[0.00297311 0.05297885 0.94404804]]
Output Z (Weighted Sum of Values):
[[0.13417439 0.42064507 0.2735804 0.41325233]
[0.31059278 1.07218276 0.7527564 0.94300817]
[0.53430871 1.89839688 1.36039887 1.61479089]]
3.2.6. Multi-Head Attention:#
where the projection matrices are: \( \quad W_i^Q \in \mathbb{R}^{d_{\text{model}} \times d_k}, \quad W_i^K \in \mathbb{R}^{d_{\text{model}} \times d_k}, \quad W_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v}, \quad \text{and} \quad W^O \in \mathbb{R}^{h d_v \times d_{\text{model}}} \)
In short, multi-head attention allows the model to attend to different aspects of the input sequence simultaneously (e.g., some heads might focus on different context type than others) and is found to be beneficial in practice.
# Pytorch implementation of causal self-attention (multi-head)
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
if not self.flash:
print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
# ! n_embd = d_model, c_attn acts as all three W_q, W_k, W_v at once and all have output dim n_embd.
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
# manual implementation of attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
return y
3.2.7. LayerNorm#
Layer Normalization (LayerNorm) is used to stabilize and accelerate training by normalizing the input across features.
Given input vector \(x \in \mathbb{R}^d\) (e.g., the hidden state of one token), compute:
Then Layer Normalization is applied as:
Where:
\(\gamma \in \mathbb{R}^d\): learnable scale
\(\beta \in \mathbb{R}^d\): learnable bias
Given an input \(X \in \mathbb{R}^{B \times L \times d_{\textrm{model}}}\), LayerNorm(\(X\)) will be applied independently for each token’s hidden state, \(x_{b,t} \in \mathbb{R}^{d_{\textrm{model}}}\), unlike BatchNorm which normalizes across a batch. Note that \(\gamma\) and \(\beta\) dimensions will remain \(d_{\textrm{model}}\) as they are shared across tokens for all sequences.
# Pytorch implementation of Layer Normalization
class LayerNorm(nn.Module):
""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
3.2.8. MLP Layer#
3.2.8.1. MLP diagram:#
3.2.8.2. Block Layer diagram:#
# Pytorch implementation of MLP Layer
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
self.attn = CausalSelfAttention(config)
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
3.2.9. Decoder-only transformer (nanoGPT)#
# Pytorch implemenation of nanoGPT
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50304 # GPT-2 vocab_size of 50257, padded up to nearest multiple of 64 for efficiency
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
dropout: float = 0.0
bias: bool = True # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and faster
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
assert config.vocab_size is not None
assert config.block_size is not None
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying
# init all weights
self.apply(self._init_weights)
# apply special scaled init to the residual projections, per GPT-2 paper
for pn, p in self.named_parameters():
if pn.endswith('c_proj.weight'):
torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * config.n_layer))
# report number of parameters
print("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
def get_num_params(self, non_embedding=True):
"""
Return the number of parameters in the model.
For non-embedding count (default), the position embeddings get subtracted.
The token embeddings would too, except due to the parameter sharing these
params are actually used as weights in the final layer, so we include them.
"""
n_params = sum(p.numel() for p in self.parameters())
if non_embedding:
n_params -= self.transformer.wpe.weight.numel()
return n_params
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
if targets is not None:
# if we are given some desired targets also calculate the loss
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-100)
else:
# inference-time mini-optimization: only forward the lm_head on the very last position
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = self(idx_cond)
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx
3.3. LLM Training#
Now that we have implemented the model, we move to the training part of the tutorial. Our goal is to take the randomly initialized model and train it on a large text dataset.
This is the first (and most expensive) stage of model training and it is known as pre-training, as we beging with a completely untrained model and train it on a large, generic dataset. Next, the model is usualy fine-tuned on more specialized or task-oriented datasets much smaller in size, and finally the model is trained to align with human preferences (alignment).
For our tutorial, we will use a subset of the cleaned english part (en) of the C4 (Colossal Clean Crawled Corpus) dataset. In particular, C4/en consists of 305GB of english sentences. After tokenization, it roughly produces 150B tokens (although the exact value will depend on the tokenizer being used). More details about C4 can be found in this link: https://huggingface.co/datasets/allenai/c4.
Next, we will go though our basic pre-training pipeline.
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from datasets import load_dataset
from transformers import get_cosine_schedule_with_warmup
from transformers import AutoTokenizer
from torch.utils.data import IterableDataset, get_worker_info
3.3.1. Training parameters#
Bellow we define our training parameters. For some of them we include more details here:
device=f"cuda:0": The ID of our GPU. Note that this simple training code does not support multi-GPU training as it is intended for training small models on relatively small amounts of data. However, in practice training LLMs entails the use of multiple GPUs using parallelization techniques. Such an implementation could be included in a future version of the tutorial.
device_batch_size=64: The number of token sequences processed simultaneously on one GPU.
total_batch_size=256: The number of token sequences the model “sees” at each training iteration. For our single GPU set-up:
gradient_accumulation = total_batch_size / device_batch_size
(4 in this case) means that before the model weights are updated, the gradients from gradient_accumulation=4 mini-batches (each having device_batch_size=64 token sequences) are summed (accumulated) and averaged, so the update reflects the effect of all total_batch_size=256 sequences together.
num_training_steps = 100: The number of training steps (model updates) that will be performed. Note that it is set to 100 just for code testing purposes. In practice, for pretraining a good guideline is the Chinchilla compute-optimal ratio, i.e. using about 20 tokens per (non-embedding) model parameter. So, since our model has 124M trainable parameters, this corresponds to about 2.5B tokens needed for training. Given that we use total_batch_size=256 and max_length=256 (the maximum sequence length), each batch size will have 65,536 tokens (or in rare cases less if some sequences are smaller than the max_length), so roughly we need 2.5B / 65,536 \(\approx 38,000\) steps. For more details about compute optimal training and the Chinchilla ratio see: https://arxiv.org/abs/2203.15556.
# Environment parameters:
device = f"cuda:0" # Our GPU id
workers = 4 # CPU workers
# Data parameters:
device_batch_size = 64
# Tokenization parameters:
max_length = 256 # sequence length L
# Optimizer parameters
lr = 1e-3
weight_decay = 0.0
# LR scheduler parameters
warmup_steps = 1000
# Training parameters:
num_training_steps = 5_000 # 38_000
total_batch_size = 256
grad_clipping = 0.0
print_freq = 100
# Evaluation parameters
eval_every = 1000
3.3.2. C4 Dataset Streaming and Preprocessing#
Load the dataset
Streams the C4/en dataset:
data = load_dataset("allenai/c4", "en", split="train", streaming=True) val_data = load_dataset("allenai/c4", "en", split="validation", streaming=True)
The data are streamed on-the-fly without downloading the full dataset on disk.
Preprocessing
PreprocessedIterableDatasettokenizes each text example using the GPT-2 tokenizer.Examples are truncated and padded to
max_length.Tokenized examples are collected into batches of size
device_batch_size.Finally, each batch is converted into a single tensor of input IDs:
input_ids = torch.stack([item["input_ids"].squeeze(0) for item in batch])
DataLoader
Using PyTorch
DataLoader:dataloader = torch.utils.data.DataLoader(dataset, batch_size=None, num_workers=workers)
Batching is done inside the dataset iterator
PreprocessedIterableDataset, so here setbatch_size=Noneas the dataloader does not need to do additional batching.
data = load_dataset(
"allenai/c4", "en", split="train", streaming=True
)
val_data = load_dataset(
"allenai/c4", "en", split="validation", streaming=True
)
class PreprocessedIterableDataset(IterableDataset):
def __init__(self, data, tokenizer, device_batch_size, max_length):
super().__init__()
self.data = data
self.tokenizer = tokenizer
self.device_batch_size = device_batch_size
self.max_length = max_length
def __iter__(self):
iter_data = iter(self.data)
batch = []
for example in iter_data:
tokenized_example = self.tokenizer(
example["text"],
max_length=self.max_length,
truncation=True,
padding="max_length",
return_tensors="pt",
)
batch.append(tokenized_example)
if len(batch) == self.device_batch_size:
yield self._format_batch(batch)
batch = []
if batch:
yield self._format_batch(batch)
def _format_batch(self, batch):
input_ids = torch.stack([item["input_ids"].squeeze(0) for item in batch])
return input_ids
# GPT-2 tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
dataset = PreprocessedIterableDataset(
data, tokenizer, device_batch_size=device_batch_size, max_length=max_length
)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=None, num_workers=workers,
)
3.3.3. Model parameters and loading#
Bellow we define nanoGPT using standard parameters. It will consist of 12 transformer layers, each having embedding dimension \(d_{\textrm{model}}=768\). It has a total of 123.55M trainable parameters.
# model parameters:
n_layer = 12
n_head = 12
n_embd = 768
dropout = 0.0
bias = False
block_size = 1024 # the maximum sequence length the model can handle
vocab_size = tokenizer.vocab_size
model_args = dict(n_layer=n_layer, n_head=n_head, n_embd=n_embd, block_size=block_size,
bias=bias, vocab_size=vocab_size, dropout=dropout)
gptconf = GPTConfig(**model_args)
model = GPT(gptconf).to(device)
model = torch.compile(model) # for faster training
n_total_params = sum(p.numel() for p in model.parameters())
trainable_params = [p for p in model.parameters() if p.requires_grad]
number of parameters: 123.55M
3.3.4. Optimizer and LR scheduler#
Bellow we define the standard Adam optimizer class (code based on transformers.optimization library) and a learning rate scheduler that consists of a linear warmup and a cosine decay phase.
Note that ee define the optimizer class here so it can serve as a foundation for creating other optimizer classes. Alternatively, you could use a predefined optimizer, for example:
optimizer = torch.optim.Adam(
params=trainable_params, lr=lr, weight_decay=weight_decay
)
We encourage experimenting with different optimizers and learning rate schedules. You can implement your own or try existing ones, for example from:
class Adam(torch.optim.Optimizer):
"""
Implements Adam algorithm with weight decay fix as introduced in [Decoupled Weight Decay
Regularization](https://arxiv.org/abs/1711.05101).
Parameters:
params (`Iterable[nn.parameter.Parameter]`):
Iterable of parameters to optimize or dictionaries defining parameter groups.
lr (`float`, *optional*, defaults to 0.001):
The learning rate to use.
betas (`Tuple[float,float]`, *optional*, defaults to `(0.9, 0.999)`):
Adam's betas parameters (b1, b2).
eps (`float`, *optional*, defaults to 1e-06):
Adam's epsilon for numerical stability.
weight_decay (`float`, *optional*, defaults to 0.0):
Decoupled weight decay to apply.
correct_bias (`bool`, *optional*, defaults to `True`):
Whether or not to correct bias in Adam (for instance, in Bert TF repository they use `False`).
"""
def __init__(
self,
params: Iterable[nn.parameter.Parameter],
lr: float = 1e-3,
betas: Tuple[float, float] = (0.9, 0.999),
eps: float = 1e-6,
weight_decay: float = 0.0,
correct_bias: bool = True,
):
if lr < 0.0:
raise ValueError(f"Invalid learning rate: {lr} - should be >= 0.0")
if not 0.0 <= betas[0] < 1.0:
raise ValueError(f"Invalid beta parameter: {betas[0]} - should be in [0.0, 1.0)")
if not 0.0 <= betas[1] < 1.0:
raise ValueError(f"Invalid beta parameter: {betas[1]} - should be in [0.0, 1.0)")
if not 0.0 <= eps:
raise ValueError(f"Invalid epsilon value: {eps} - should be >= 0.0")
defaults = {"lr": lr, "betas": betas, "eps": eps, "weight_decay": weight_decay, "correct_bias": correct_bias}
super().__init__(params, defaults)
@torch.no_grad()
def step(self, closure: Callable = None):
"""
Performs a single optimization step.
Arguments:
closure (`Callable`, *optional*): A closure that reevaluates the model and returns the loss.
"""
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad
state = self.state[p]
if "step" not in state:
state["step"] = 0
# State initialization
if "exp_avg" not in state:
# Exponential moving average of gradient values
state["exp_avg"] = torch.zeros_like(grad)
# Exponential moving average of squared gradient values
state["exp_avg_sq"] = torch.zeros_like(grad)
exp_avg, exp_avg_sq = state["exp_avg"], state["exp_avg_sq"]
beta1, beta2 = group["betas"]
state["step"] += 1
# Decay the first and second moment running average coefficient
# In-place operations to update the averages at the same time
exp_avg.mul_(beta1).add_(grad, alpha=(1.0 - beta1))
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1.0 - beta2)
denom = exp_avg_sq.sqrt().add_(group["eps"])
step_size = group["lr"]
if group["correct_bias"]:
bias_correction1 = 1.0 - beta1 ** state["step"]
bias_correction2 = 1.0 - beta2 ** state["step"]
step_size = step_size * math.sqrt(bias_correction2) / bias_correction1
# Adam update
u = exp_avg / denom
p.add_(u, alpha=-step_size)
if group["weight_decay"] > 0.0:
p.add_(p, alpha=(-group["lr"] * group["weight_decay"]))
return loss
# optimizer using our Adam class defined above
optimizer = Adam(trainable_params, lr=lr, weight_decay=weight_decay)
# learning rate scheduler
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=warmup_steps,
num_training_steps=num_training_steps,
last_epoch=-1,
)
3.3.5. Main Training Code#
Before the training loop:
Initialization: Initialize
global_step,update_step, andtokens_seen. Set upgradient_accumulationbased ontotal_batch_sizeanddevice_batch_size. Note thatupdate_stepcounts the actual number of updates performed, whileglobal_step = update_step * gradient_accumulation.
Inside the training loop:
Batch Processing
Load a batch from the
dataloaderand move it to the device.Prepare labels by shifting input tokens left (next-token prediction) and masking padding (
-100for ignored positions):input_ids = batch.to(device) labels = input_ids.clone() labels[:, :-1] = input_ids[:, 1:] # shift left labels[:, -1] = pad_idx # pad the last token labels[labels == pad_idx] = -100 # mask out padding labels = labels.to(device)
Forward and Backward Pass:
Compute logits and loss after passing the input and labels to the model (forward pass). Then scale the loss by
gradient_accumulationand call.backward()for the backward pass.logits, loss = model(input_ids, targets=labels) scaled_loss = loss / gradient_accumulation scaled_loss.backward()
Accumulate gradients over multiple mini-batches if needed:
if global_step % gradient_accumulation != 0: continue
Optimizer Step:
Apply gradient clipping if configured.
Update model parameters with
optimizer.step()and learning rate schedulerscheduler.step().Reset gradients with
optimizer.zero_grad().Increment
update_step.if grad_clipping != 0.0: torch.nn.utils.clip_grad_norm_(trainable_params, grad_clipping) optimizer.step() scheduler.step() optimizer.zero_grad() update_step += 1
Logging: Print progress every
print_frequpdates.Termination: Stop training when
num_training_stepsis reached.
# Evaluation code
def collate_fn(batch_list):
batch = torch.stack([torch.Tensor(example["input_ids"]).long() for example in batch_list])
return batch
def batch_fn(dataset, batch_size):
batch = []
for example in dataset:
batch.append(example)
if len(batch) == batch_size:
batch = collate_fn(batch)
yield batch
batch = []
if len(batch) > 0:
yield batch
def preprocess_batched(batch):
batch = tokenizer(
batch["text"],
max_length=max_length,
truncation=True,
padding="max_length",
return_tensors="pt",
)
return batch
@torch.no_grad()
def evaluate_model(
model, val_data, preprocess_batched, pad_idx, device, batch_size
):
val_data = val_data.shuffle(seed=42)
val_data_mapped = val_data.map(
preprocess_batched,
batched=True,
remove_columns=["text", "timestamp", "url"],
)
val_data_mapped.batch = lambda batch_size: batch_fn(
val_data_mapped, batch_size
)
target_eval_tokens = 1_000_000 #10_000_000
evaluated_on_tokens = 0
total_loss = torch.tensor(0.0).to(device)
total_batches = 0
for batch in val_data_mapped.batch(batch_size=batch_size):
if evaluated_on_tokens > target_eval_tokens:
break
total_batches += 1
input_ids = batch.to(device)
labels = input_ids.clone()
labels[:, :-1] = input_ids[:, 1:] # shift left
labels[:, -1] = pad_idx # pad the last token
labels[labels == pad_idx] = -100 # mask out padding
labels = labels.to(device)
_, loss = model(input_ids, targets=labels)
total_loss += loss.detach()
evaluated_on_tokens += (batch != pad_idx).sum().item()
total_loss = total_loss / total_batches
return total_loss, evaluated_on_tokens
# ##############################
# Initialization
# ##############################
global_step = 0 # = update_step * gradient_accumulation
update_step = 0
tokens_seen = 0 # = global_step / gradient_accumulation
tokens_seen_before = 0
world_size = 1 # The number of GPUs we will use, here is set to 1 as multi-GPU training is not implemented.
pad_idx = tokenizer.pad_token_id
gradient_accumulation = None
if total_batch_size is not None:
if gradient_accumulation is None:
assert (
total_batch_size % world_size == 0
), "total_batch_size must be divisible by world_size"
gradient_accumulation = total_batch_size // (
device_batch_size * world_size
)
assert (
gradient_accumulation > 0
), "gradient_accumulation must be greater than 0"
assert (
gradient_accumulation * device_batch_size * world_size
== total_batch_size
), "gradient_accumulation * device_batch_size * world_size must be equal to total_batch_size"
# ##############################
# START of training loop
# ##############################
losses = []
eval_losses = []
for batch_idx, batch in enumerate(dataloader):
global_step += 1
if update_step > num_training_steps:
print(
f"Reached max number of update steps (f{num_training_steps}). Stopping training."
)
break
input_ids = batch.to(device)
labels = input_ids.clone()
labels[:, :-1] = input_ids[:, 1:] # shift left
labels[:, -1] = pad_idx # pad the last token
labels[labels == pad_idx] = -100 # mask out padding
labels = labels.to(device)
tokens_seen += (input_ids != pad_idx).sum().item()
with torch.amp.autocast("cuda", dtype=torch.bfloat16): # Automatic mixed precision
logits, loss = model(input_ids, targets=labels)
scaled_loss = loss / gradient_accumulation
scaled_loss.backward()
if global_step % gradient_accumulation != 0:
continue
losses.append((loss.item(), update_step))
if update_step % print_freq == 0:
print(f"Update step: {update_step}/{num_training_steps} | loss: {loss.item()}")
#######
if grad_clipping != 0.0:
torch.nn.utils.clip_grad_norm_(trainable_params, grad_clipping)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
update_step += 1
if eval_every > 0 and ((update_step % eval_every == 0) or (update_step == num_training_steps) ):
total_loss, evaluated_on_tokens = evaluate_model(
model, val_data, preprocess_batched, pad_idx, device, device_batch_size,
)
total_loss = total_loss.detach().cpu().numpy()
eval_losses.append((total_loss.item(), update_step))
print(f"[Eval Step {update_step}] Loss: {total_loss:.4f}, PPL: {np.exp(total_loss):.2f}, Eval tokens {evaluated_on_tokens}", )
# ##############################
# END of training loop
# ##############################
print("Training finished")
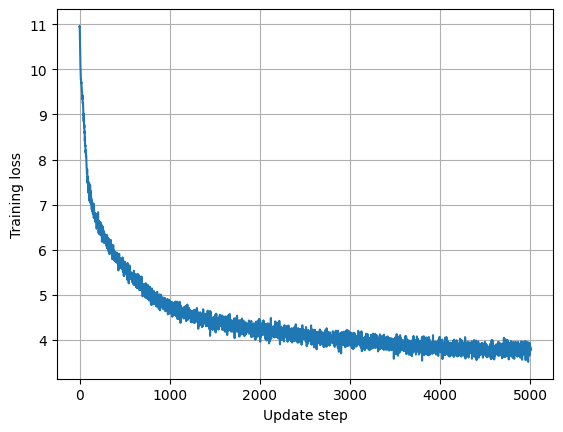
Update step: 0/5000 | loss: 10.952651023864746
Update step: 100/5000 | loss: 7.476326942443848
Update step: 200/5000 | loss: 6.552395343780518
Update step: 300/5000 | loss: 6.281008243560791
Update step: 400/5000 | loss: 5.8591413497924805
Update step: 500/5000 | loss: 5.669686317443848
Update step: 600/5000 | loss: 5.336837291717529
Update step: 700/5000 | loss: 5.1455979347229
Update step: 800/5000 | loss: 4.938043117523193
Update step: 900/5000 | loss: 4.867392539978027
/users/3/glent007/.conda/envs/pretrain/lib/python3.9/site-packages/torch/_inductor/compile_fx.py:150: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
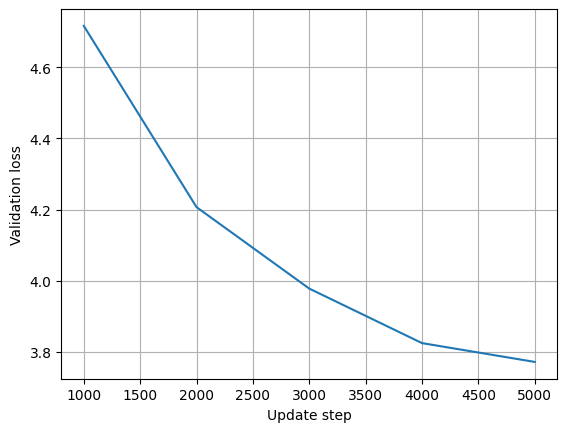
[Eval Step 1000] Loss: 4.7168, PPL: 111.81, Eval tokens 1002149
Update step: 1000/5000 | loss: 4.580242156982422
Update step: 1100/5000 | loss: 4.6037421226501465
Update step: 1200/5000 | loss: 4.505423545837402
Update step: 1300/5000 | loss: 4.5377726554870605
Update step: 1400/5000 | loss: 4.495709419250488
Update step: 1500/5000 | loss: 4.415157318115234
Update step: 1600/5000 | loss: 4.35715913772583
Update step: 1700/5000 | loss: 4.266164302825928
Update step: 1800/5000 | loss: 4.152810573577881
Update step: 1900/5000 | loss: 4.162186622619629
[Eval Step 2000] Loss: 4.2067, PPL: 67.13, Eval tokens 1002149
Update step: 2000/5000 | loss: 4.339847564697266
Update step: 2100/5000 | loss: 4.061264991760254
Update step: 2200/5000 | loss: 4.050267219543457
Update step: 2300/5000 | loss: 4.3048996925354
Update step: 2400/5000 | loss: 4.263776779174805
Update step: 2500/5000 | loss: 4.136542320251465
Update step: 2600/5000 | loss: 3.8340630531311035
Update step: 2700/5000 | loss: 4.06512451171875
Update step: 2800/5000 | loss: 4.01227331161499
Update step: 2900/5000 | loss: 3.698397159576416
[Eval Step 3000] Loss: 3.9774, PPL: 53.38, Eval tokens 1002149
Update step: 3000/5000 | loss: 3.9442801475524902
Update step: 3100/5000 | loss: 4.044785499572754
Update step: 3200/5000 | loss: 3.902740478515625
Update step: 3300/5000 | loss: 3.8698809146881104
Update step: 3400/5000 | loss: 4.043209075927734
Update step: 3500/5000 | loss: 3.8836166858673096
Update step: 3600/5000 | loss: 3.841282844543457
Update step: 3700/5000 | loss: 3.9159064292907715
Update step: 3800/5000 | loss: 4.0341081619262695
Update step: 3900/5000 | loss: 3.780771017074585
[Eval Step 4000] Loss: 3.8240, PPL: 45.78, Eval tokens 1002149
Update step: 4000/5000 | loss: 3.9799275398254395
Update step: 4100/5000 | loss: 3.6987831592559814
Update step: 4200/5000 | loss: 3.8864691257476807
Update step: 4300/5000 | loss: 3.8983962535858154
Update step: 4400/5000 | loss: 3.72361159324646
Update step: 4500/5000 | loss: 3.9271936416625977
Update step: 4600/5000 | loss: 3.7813913822174072
Update step: 4700/5000 | loss: 3.794313907623291
Update step: 4800/5000 | loss: 3.8042850494384766
Update step: 4900/5000 | loss: 3.6387569904327393
2025-11-16 21:13:54.063 | INFO | __main__:<module>:44 - Reached max number of update steps (f5000). Stopping training.
[Eval Step 5000] Loss: 3.7710, PPL: 43.42, Eval tokens 1002149
Update step: 5000/5000 | loss: 3.786674737930298
2025-11-16 21:13:54.353 | INFO | __main__:<module>:95 - Training finished
import matplotlib.pyplot as plt
losses_ = [l for (l,s) in losses]
plt.plot(losses_)
plt.grid()
plt.xlabel("Update step")
plt.ylabel("Training loss")
plt.show()
eval_losses_ = [l for (l,s) in eval_losses]
eval_steps = [s for (l,s) in eval_losses]
plt.plot(eval_steps, eval_losses_)
plt.grid()
plt.xlabel("Update step")
plt.ylabel("Validation loss")
plt.show()